2-1. API
(1) API : 프로그램 간 데이터 전달을 위한 규칙.
→ 빈번하게 반복되는 작업에는 공개 API 사용여부를 체크하기.
(2) HTTP : 웹에서 데이터 주고 받기 위한 프로토콜(=통신규약)
* HTML : 웹서버로부터 회신받는 데이터
웹서버 → 웹브라우저 → HTML이 그래픽으로 화면에 표시됨.

(3) JSON : 근래에 많이 사용되는 데이터 전달 포맷
→ 자바 스크립트와 웹기반 API 에서
1) 장점 : HTML, XML과 비교하여 사람이 읽기 편함.
→ 간단히 파이썬 객체로 변환 가능
2) json.dumps()와 json.loads() 메소드

3) [ ] : 'JSON 배열'이라고 함. ( 파이썬 list 와 유사)
{ } : 'JSON 객체'라고 함. (파이썬 dictionary와 유사)
4) JSON 함수 정리
① 파이썬 객체를 json 문자열로 전환
문자열 = json.dumps( 문자열로_변환할_것, ensure_ascii = False)
② json 문자열을 파이썬 객체로 전환
파이썬객체 = json.loads(객체로_전환할_문자열)
③ json 문자열을 바로 판다스로
판다스 = pd.read_json(json_문자열)
(4) XML : JSON 보다 장황. 사람도 이해하기 쉬운 구조적인 포맷
1) 상하위 관계 - 부모-자식 엘리먼트
2) <시작 태그> → </끝태그>
예시.
<book>
<name> 혼자 공부하는 데이터분석 </name>
<author>박해선</author>
</book>
3) 함수 정리
# xml의 자식 엘리먼트 확인하기 : findtext('찾을문자열')
for book in books.findall('book'):
name = book.findtext('name')
author = book.findtext('author')
print('name')
print('author')
# xml 텍스트를 판다스로 바로 읽기 : pd.read_xml(xml_문자열)
df = pd.read_xml(xml_문자열)
(5) 파이썬으로 API 호출하기 : requests 패키지 이용
1)
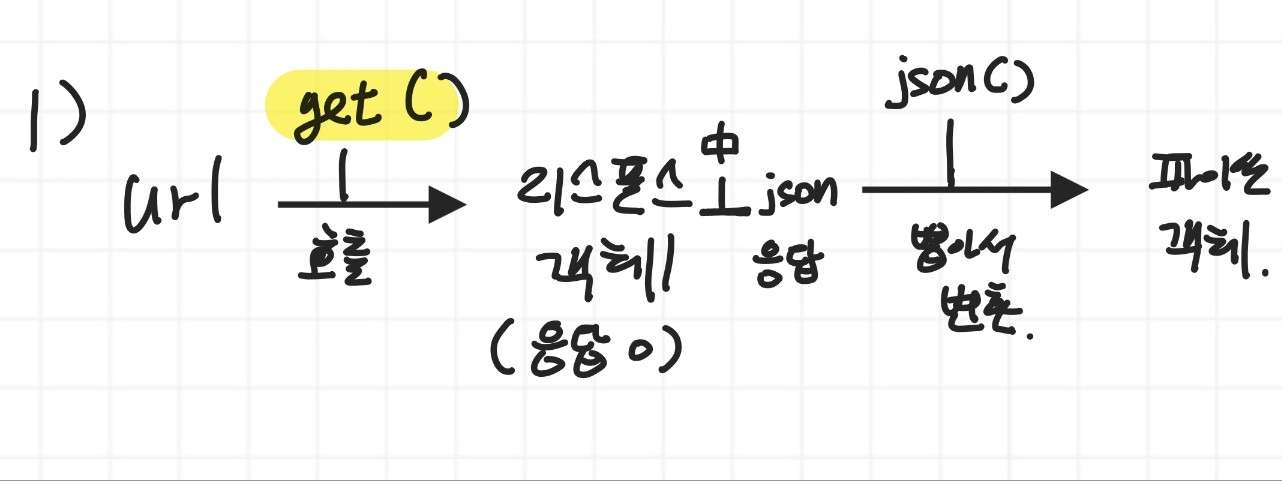
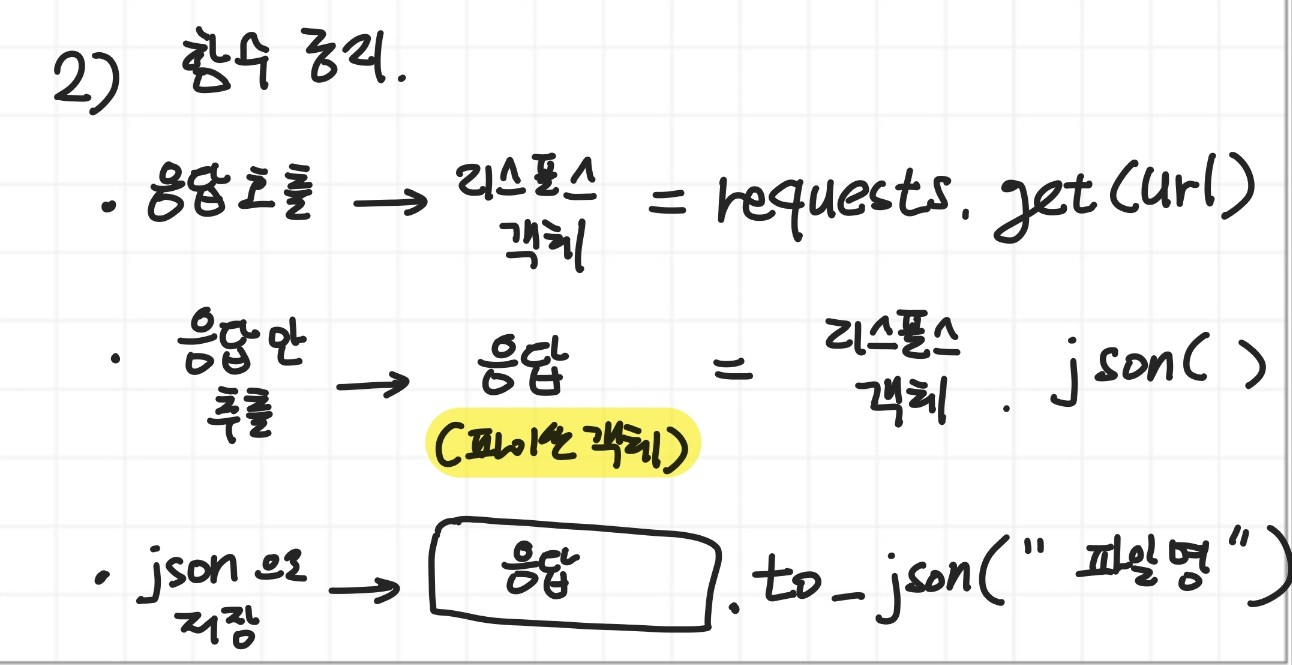
2) 손코딩
import requests
url = "http:// ~~"
r = requests.get(url) #여기서 r은 Response 클래스의 객체
data = r.json() # 파이썬 객체로 변환
books = [ ]
for d in data['response']['docs']:
books.append(d['doc'])
books_df = pd.DataFrame(books)
2-2. 웹 스크래핑 : 20대 인기도서의 페이지수 찾기.
(1) 20대 인기도서 데이터프레임으로 불러오기
0단계. 20대 인기도서 불러오기 : gdown 패키지 이용
import gdown
gdown.download('https://bit.ly/3q9SZix', '20s_best_book.json', quiet = False)
from bs4 import BeautifulSoup
import requests
def get_page_cnt(isbn):
url = f'https://www.yes24.com/Product/Search?domain=ALL&query={isbn}'
r = requests.get(url) #리퀘스트겟 함수로 HTML 따기
soup = BeautifulSoup(r.text, 'html.parser')
prd_link = soup.find('a',attrs={'class':"gd_name"}) #도서 상세페이지 url 담은 a 태그 찾기
# href의 값이 바로 상세페이지 url
url = 'https://www.yes24.com/' + prd_link['href']
r = requests.get(url)
# 뷰티풀수프로 HTML 파싱하기
soup = BeautifulSoup(r.text,'html.parser')
# 뷰티풀수프 객체에서 특정 태그 찾는 메소드 : find('찾을 태그명',attrs = {속성 : 값})
prd_detail = soup.find('div',attrs={'id':'infoset_specific'})
tr_prd_lst = prd_detail.find_all('tr')
for tr in tr_prd_lst:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split(' ')[0]
return ''
get_page_cnt(9791190090018)
20대 인기도서 중 top 5만 사용할것.
(※ top10으로 하려고 하였으나, 8번째 서적인 나미야 잡화점의 기적이 ISBN이 변경되어 오류가 발생하였음.)
import pandas as pd
book_df = pd.read_json('20s_best_book.json')
book_df.loc[[0],['bookname','isbn13']]top_5_books = book_df[:5]
#오래걸림
page_count = top_5_books.apply({'isbn13': get_page_cnt})
page_count.columns = ['page_count']
top_5_with_page_count = pd.merge(top_5_books, page_count, left_index = True, right_index = True)
top_5_with_page_count
아래는 위 코드를 코랩에서 실행한 결과이다.

'혼공분석 with 파이썬 공부' 카테고리의 다른 글
| [혼공분석] with 파이썬 4주차 공부 ( 4주차 추가 숙제 포함) (0) | 2024.07.26 |
|---|---|
| [혼공분석] with 파이썬 3주차 공부 (0) | 2024.07.21 |
| [혼공분석] with 파이썬 1주차 내용 정리 ( 새로 알게된 사실 위주) (0) | 2024.07.07 |

